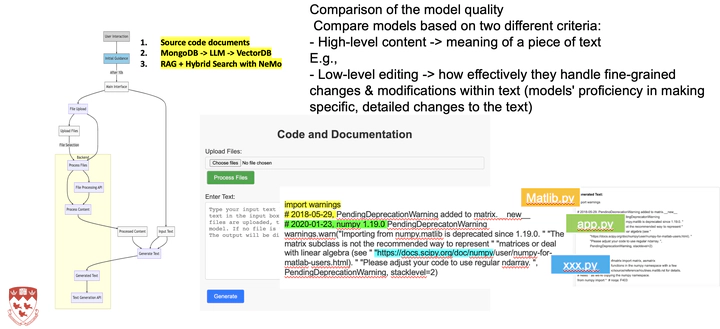
 The diagram of Code and Documentation Generation
The diagram of Code and Documentation GenerationMachine learning techniques have been proposed to support a variety of software engineering tasks, such as code search, documentation generation, code migration, etc. While advances have been observed using publicly available datasets and common metrics, the impact of those techniques in practice is unclear. The context of tasks can be vastly different depending on the project phases, the expertise of the developers, and the objective of the tasks. Therefore, machine learning techniques need to consider the context of the tasks to make meaningful breakthroughs for supporting software engineers. The documentation task, in particular, concerns the generation of documentation given the source code. When the developers are writing high-quality documentation, they seldomly just repeat the source code. Instead, they record the usage of the code or the rationale of why the code is written in a certain way. Such information is critical to support the users to appropriately adapt their APls and enable the code maintainers to understand the code and respect the constraints. In this project, we aim to understand the limitations of the existing machine learning based documentation generation techniques. We investigate how they can support the users to create information that is both relevant and high quality.
Through this internship, we are more familiar with basic natural language processing (summarization) techniques and basic understanding of empirical methods. We are able to collect data from real software engineering projects and evaluate model performance within a software engineering task context.
